A batch of URLs is published. They appear in Google Search Console. They sit under Discovered – currently not indexed. Nothing obvious is broken, there is no clear error, and yet nothing gets crawled. For teams shipping content, product pages, or large site sections, this is one of the most frustrating indexing states because it feels like a silent queue you cannot see.
The good news is that this status is usually more architectural than mysterious. If Google has discovered the URL, the problem is not that the page is invisible. The problem is often that Google has decided not to fetch it yet.
TL;DR
- Discovered – currently not indexed means Google knows the URL exists but has not crawled it yet.
- This is usually a crawl scheduling / crawl efficiency problem, not a direct content-quality verdict.
- The most common causes are slow server response, too many low-value URLs, weak internal linking, and poor sitemap hygiene.
If your sitemap layer is already noisy or stale, fix that first. XML Sitemap Best Practices for Modern, Dynamic Websites covers the clean URL selection rules that help Google spend crawl effort in the right places.
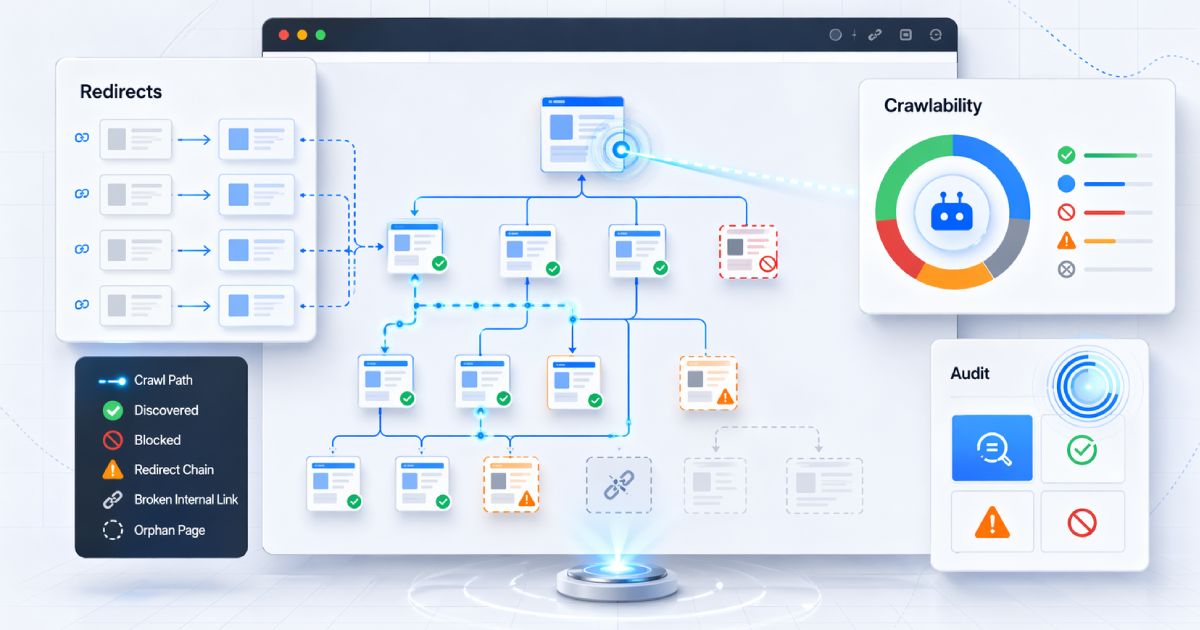
The crucial distinction: Discovered vs Crawled
These two Search Console states are often lumped together, but they describe different stages of Google's workflow and should not be diagnosed the same way.
| Status | What Google has done | What it usually means | Primary fix direction |
|---|---|---|---|
| Discovered – currently not indexed | Found the URL, but has not fetched it yet. | Crawl queueing, crawl backoff, weak priority signals, or too many low-value URLs. | Improve crawl efficiency, server responsiveness, internal linking, and sitemap quality. |
| Crawled – currently not indexed | Fetched the URL, but did not select it for the index. | Post-crawl indexing decision, duplication, weak distinctiveness, or canonical conflicts. | Review canonicalization, duplication, rendering output, and the value of the page after fetch. |
The extractable rule is simple: Discovered means found but not yet fetched. Crawled means fetched but not chosen for the index yet. One is mainly about crawl scheduling. The other is mainly about what Google saw after fetching the page.
Why this status happens: Google has queued the URL, then backed off
Google can discover URLs through XML sitemaps, internal links, redirects, feeds, and other crawl paths. Once found, the URL can enter Google's crawl queue. That queue entry is not a guarantee of immediate fetch.
Discovered – currently not indexed usually means the URL made it into the queue, but Google decided not to hit the site harder right now. That decision is often shaped by crawl demand, crawl capacity, and overall site efficiency rather than any personal dislike of the page.
This is especially common when a site exposes a large number of URLs relative to the amount of crawl demand it has earned, or when the infrastructure makes each fetch look expensive. Architecturally, the pattern is: discovery happened, then scheduling backed off.
Culprit 1: server responsiveness and crawl backoff
One of the strongest drivers of delayed crawling is server responsiveness. If Google sees high TTFB, intermittent 5xx responses, queueing, or generally unstable fetch behavior, it may crawl more cautiously. Crawlers are designed to avoid overloading systems that already look expensive to fetch.
This shows up often on dynamic stacks with uncached HTML, heavy database work, or slow origin rendering. A single-region origin can contribute if users and crawlers are fetching over long distances without effective caching, but geography alone is rarely the whole story. The more useful question is whether the site looks consistently cheap and stable to fetch at crawl time.
Practical fixes
- Reduce TTFB for HTML responses, not just static assets.
- Cache HTML where appropriate for pages that do not need per-request rendering.
- Use a CDN intelligently so the origin is not the bottleneck for every fetch.
- Profile slow database queries, API fan-out, and rendering bottlenecks.
- Inspect server logs during crawl spikes instead of guessing from dashboards alone.
- Stabilize intermittent
5xxbehavior before expecting indexing gains.
Do not optimize around averages only
Culprit 2: crawl traps and low-value URL explosion
Crawl budget problems are often self-inflicted by URL architecture. Faceted navigation, filters, sort parameters, calendar pages, search-result URLs, and endless parameter combinations can create a huge space of discoverable but low-value URLs.
When Google finds thousands of slight variations, important URLs may remain queued while crawl effort is spent elsewhere. Ecommerce filters, internal site search pages, endless sort combinations, and duplicate route variations are common examples.
Fix direction
- Tighten URL architecture so only valuable route patterns are broadly discoverable.
- Use
robots.txtcarefully for crawl control where it makes architectural sense. - Canonicalize duplicates correctly, but do not rely on canonical tags to fix junk URL sprawl alone.
- Avoid feeding low-value parameter URLs into internal links and sitemaps.
If you are using robots.txt as part of crawl control, avoid broad blocking mistakes that create new problems while solving the old one. 7 Critical robots.txt Mistakes That Are Silently Killing Your SEO covers the failure modes teams introduce when they try to manage crawl with blunt rules.
Culprit 3: internal link famine and orphan-like pages
A URL that appears only in a sitemap but gets little or no meaningful internal linking often looks unimportant. Sitemaps help discovery, but internal links are still one of the clearest signals of crawl priority and relative importance inside a site.
This is why new URLs buried several clicks deep, absent from hubs, and disconnected from normal navigation paths often wait longer to be crawled. The issue is not just abstract PageRank language. It is the practical reality that Google sees very few strong site-level reasons to fetch the page soon.
Practical fixes
- Link new pages from relevant hub pages, categories, or collections.
- Add related content or related product modules that create contextual crawl paths.
- Improve category, pagination, and recency surfaces for newly published URLs.
- Ensure important pages are reachable through normal navigation, not only XML discovery.
Culprit 4: sitemap hygiene problems
Sitemaps should help Google prioritize crawlable, canonical, 200-status URLs. They stop helping when they become a dumping ground for every route the stack can generate.
Low-quality sitemaps waste crawl attention when they contain redirects, noindex URLs, broken URLs, parameter junk, or duplicates. A sitemap is a quality hint. If the hint is noisy, Google has less reason to trust it as a prioritization source.
Practical fixes
- Include only canonical
200pages you actually want indexed. - Remove redirects, broken URLs, duplicates, and non-canonical variants.
- Use sitemap indexes to segment large sites cleanly by content type or section.
- Update sitemaps dynamically so new and removed URLs are reflected quickly.
The CodeAva Sitemap Checker is the fastest way to spot whether your sitemap is carrying redirect chains, dead URLs, or other structural noise that weakens discovery quality.
The fix workflow: what to do in order
The right response is a workflow, not a button click. Work through the system from diagnosis to architecture cleanup.
- Confirm the status in Search Console or URL Inspection so you are solving Discovered, not Crawled.
- Check whether the URL is present in a clean, canonical sitemap.
- Verify the page is linked from relevant internal pages and not effectively orphaned.
- Review server logs,
5xxpatterns, and TTFB during crawl windows. - Identify crawl traps, parameter junk, and low-value URL explosions.
- Improve crawl paths to the affected URLs through hubs, navigation, and related links.
- Request indexing selectively for high-priority URLs after the structural fixes are live.
What not to rely on
What not to do
- Do not assume “Discovered” means the content is low quality.
- Do not keep stuffing more URLs into the sitemap without fixing architecture.
- Do not rely on repeated manual reindex requests as a scalable fix.
- Do not expose endless parameter URLs and expect Google to sort them out for you.
- Do not blame content alone when the issue is clearly crawl scheduling or site structure.
Auditing the architecture
If thousands of URLs are stuck in Discovered – currently not indexed, that is usually an architectural signal, not a publishing cadence problem. The site is telling Google to discover more than it can efficiently prioritize and fetch.
Use a CodeAva Website Audit to review crawl-related technical signals across the site, then validate sitemap quality with the Sitemap Checker and review crawl controls with the Robots.txt Checkerbefore you push more URLs into Google's queue.
Conclusion and next steps
Discovered – currently not indexed usually points to crawl efficiency, discovery quality, and server responsiveness rather than a direct content verdict. If Google has discovered the URL but not crawled it, the most useful fixes are usually structural.
Clean sitemaps, stronger internal links, faster responses, and fewer junk URLs create the conditions for indexing to happen. Audit your site with CodeAva Website Audit, check your sitemap with the Sitemap Checker, and review crawl controls with the Robots.txt Checker.